
Este artículo explica las restricciones SQL NOT NULL, Unique y SQL Primary Key en SQL Server con ejemplos
Las restricciones en SQL Server son reglas y restricciones predefinidas que se aplican en una sola columna o en varias columnas, relacionados a los valores permitidos en las columnas, para mantener la integridad, precisión y confiabilidad de los datos de esa columna. En otras palabras, si los datos insertados cumplen con la regla de restricción, se insertarán con éxito. Si los datos insertados violan la restricción definida, la operación de inserción se cancelará.
Las restricciones en SQL Server se pueden considerar a nivel de columna, donde se especifica como parte de la definición de columna y se aplicarán solo a esa columna, o se declararán de forma independiente a nivel de tabla. En este caso, las reglas de restricción se aplicarán a más de una columna en la tabla especificada. La restricción se puede crear dentro del comando CREATE TABLE T-SQL al crear la tabla o agregarse usando el comando ALTER TABLE T-SQL después de crear la tabla. Al agregar la restricción después de crear la tabla, se verificará previamente la regla de restricción en los datos existentes antes de crear esa restricción.
Hay seis restricciones principales que se usan comúnmente en SQL Server que describiremos en profundidad con ejemplos en este artículo y en el siguiente. Estas restricciones son:
- SQL NOT NULL
- UNIQUE
- PRIMARY KEY
- FOREIGN KEY
- CHECK
- DEFAULT
En este artículo, veremos las tres primeras restricciones; SQL NOT NULL, UNIQUE y SQL PRIMARY KEY, y completaremos las tres restricciones restantes en el próximo artículo. Comencemos discutiendo cada una de estas restricciones de SQL Server con una breve descripción y una demostración práctica.
Restricción NOT NULL en SQL
Por defecto, las columnas pueden contener valores NULL. Se usa una restricción NOT NULL en SQL para evitar insertar valores NULL en la columna especificada, considerándolo entonces como un valor no aceptado para esa columna. Esto significa que debe proporcionar un valor válido SQL NOT NULL a esa columna en las instrucciones INSERT o UPDATE, ya que la columna siempre contendrá datos.
Suponga que tenemos la siguiente instrucción simple de CREATE TABLE que se utiliza para definir la tabla ConstraintDemo1. Esta tabla contiene solo dos columnas, ID y Nombre. En la instrucción de definición de la columna ID, se aplica la restricción de nivel de columna SQL NOT NULL, considerando la columna ID como una columna obligatoria que debe proporcionarse con un valor válido SQL NOT NULL. El caso es diferente para la columna Nombre que puede ignorarse en la instrucción INSERT, con la capacidad de proporcionarle un valor NULL. Si no se especifica la capacidad nula al definir la columna, la misma aceptará el valor NULL de forma predeterminada:
|
1 2 3 4 5 6 7 8 9 |
USE SQLShackDemo GO CREATE TABLE ConstraintDemo1 ( ID INT NOT NULL, Name VARCHAR(50) NULL ) |
Si intentamos realizar las siguientes tres operaciones de inserción:
|
1 2 3 4 5 6 7 8 |
INSERT INTO ConstraintDemo1 ([ID],[NAME]) VALUES (1,'Ali') GO INSERT INTO ConstraintDemo1 ([ID]) VALUES (2) GO INSERT INTO ConstraintDemo1 ([NAME]) VALUES ('Fadi') GO |
Usted Verá que el primer registro se insertará correctamente, ya que los valores de las columnas ID y Nombre se proporcionan en la instrucción INSERT. El proporcionar solamente la ID en la segunda instrucción INSERT no impedirá que el proceso de inserción se complete con éxito, debido a que la columna Nombre no es obligatoria y acepta valores NULL. La última operación de inserción fallará, ya que solo proporcionamos en la instrucción INSERT un valor para la columna Nombre, sin proporcionar el valor para la columna ID el mismo que es obligatorio y no se le puede asignar un valor NULL, como se muestra en el mensaje de error a continuación:

Al verificar los datos insertados, usted verá que solo se insertan dos registros y el valor que falta para la columna Nombre en la segunda instrucción INSERT será NULL, que es el valor predeterminado, como se muestra en el resultado a continuación:

Suponga que necesitamos evitar que la columna Nombre de la tabla anterior acepte valores NULL después de crear la tabla, entonces utilizando la siguiente instrucción T-SQL ALTER TABLE:
|
1 2 3 |
ALTER TABLE ConstraintDemo1 ALTER COLUMN [Name] VARCHAR(50) NOT NULL |
Usted Verá que el comando fallará, ya que el mismo primero comprobará los valores existentes de la columna Nombre para valores NULL previamente antes de crear la restricción, como se muestra en el mensaje de error a continuación:

Para reforzar y aplicar las restricciones NOT NULL en SQL, debemos eliminar todos los valores NULL de la columna Nombre de la tabla, utilizando la siguiente instrucción UPDATE, que reemplaza los valores NULL con una cadena vacía:
|
1 2 3 |
UPDATE ConstraintDemo1 SET [Name]='' WHERE [Name] IS NULL |
Si usted intenta crear las Restricciones en SQL nuevamente, la misma se creará con éxito como se muestra a continuación:

La restricción SQL NOT NULL también se puede crear utilizando SQL Server Management Studio, haciendo clic en el botón derecho en la tabla necesaria y seleccionando la opción Diseño. Al lado de cada columna, usted encontrará una pequeña casilla de verificación que puede usar para especificar la capacidad nula de esa columna. Al desmarcar la casilla de verificación junto a la columna, entonces se creará automáticamente una restricción SQL NOT NULL, evitando que se inserte cualquier valor NULL en esa columna, como se muestra a continuación:

Restricciones ÚNICAS en SQL
La restricción UNIQUE en SQL se utiliza para garantizar que no se inserten valores duplicados en una columna específica o combinación de columnas que participen en la restricción UNIQUE y no formen parte de la CLAVE PRIMARIA. En otras palabras, el índice que se crea automáticamente cuando define una restricción ÚNICA garantizará que no haya dos filas en esa tabla que puedan tener el mismo valor para las columnas que participan en ese índice, con la capacidad de insertar solo un valor NULL único en estos columnas, esto si la columna permite NULL.
Creemos una pequeña tabla con dos columnas, ID y Nombre. La columna de ID no puede contener valores duplicados debido a la restricción ÚNICA especificada con la definición de columna. No hay restricciones definidas en la columna Nombre, como en la siguiente instrucción CREATE TABLE T-SQL:
|
1 2 3 4 5 6 7 8 9 |
USE SQLShackDemo GO CREATE TABLE ConstraintDemo2 ( ID INT UNIQUE, Name VARCHAR(50) NULL ) |
Si intentamos ejecutar las cuatro instrucciones INSERT a continuación:
|
1 2 3 4 5 6 7 8 9 10 |
INSERT INTO ConstraintDemo2 ([ID],[NAME]) VALUES (1,'Ali') GO INSERT INTO ConstraintDemo2 ([ID],[NAME]) VALUES (2,'Ali') GO INSERT INTO ConstraintDemo2 ([ID],[NAME]) VALUES (NULL,'Adel') GO INSERT INTO ConstraintDemo2 ([ID],[NAME]) VALUES (1,'Faris') GO |
Los dos primeros registros se insertarán correctamente, sin las restricciones que impidan los valores duplicados de la columna Nombre. El tercer registro también se insertará correctamente, ya que la única columna de ID solo permite un valor NULL. La última instrucción INSERT fallará, ya que la columna ID no permite valores duplicados y el valor ID proporcionado ya está insertado en esa columna, como se muestra en el mensaje de error a continuación:

Las tres filas insertadas serán las que se muestran a continuación:

El objeto del sistema INFORMATION_SCHEMA.TABLE_CONSTRAINTS puede ser usado fácilmente para recuperar información sobre todas las restricciones definidas en una tabla específica utilizando el script T-SQL a continuación:
|
1 2 3 4 5 6 7 8 |
SELECT CONSTRAINT_NAME, TABLE_SCHEMA , TABLE_NAME, CONSTRAINT_TYPE FROM INFORMATION_SCHEMA.TABLE_CONSTRAINTS WHERE TABLE_NAME='ConstraintDemo2' |
El resultado de la consulta anterior nos mostrará la restricción UNIQUE definida en SQL en la tabla proporcionada, que será como:

Usando el nombre de restricción recuperado del objeto del sistema INFORMATION_SCHEMA.TABLE_CONSTRAINTS, podemos eliminar la restricción ÚNICA usando ALTER TABLE… DROP CONSTRAINT en el comando SQL T-SQL a continuación:
|
1 2 3 |
ALTER TABLE ConstraintDemo2 DROP CONSTRAINT [UQ__Constrai__3214EC26B928E528] |
Si usted previamente intenta ejecutar la instrucción INSERT fallida anteriormente, el registro con el valor de ID duplicado se insertará correctamente:

Intentando agregar la restricción ÚNICA en SQL nuevamente usando ALTER TABLE… ADD CONSTRAINT Comando T-SQL a continuación:
|
1 2 3 4 |
ALTER TABLE ConstraintDemo2 ADD CONSTRAINT UQ__Constrai UNIQUE (ID) GO |
La restricción en la creación de SQL fallará debido a que tiene valores duplicados de esa columna en la tabla, tal como se muestra en el mensaje de error a continuación:

Verificando los datos insertados, vemos que los valores duplicados serán claros como se muestra a continuación:

Para añadir la restricción ÚNICA, se tiene la opción de eliminar o modificar los valores duplicados. En nuestro caso, actualizaremos el segundo valor de ID duplicado usando la siguiente instrucción de ACTUALIZAR:
|
1 2 3 |
UPDATE [SQLShackDemo].[dbo].[ConstraintDemo2] SET ID =3 WHERE NAME='FARIS' |
Ahora, la restricción UNIQUE en SQL se puede agregar sin error a la columna ID como se ve líneas abajo:

La clave ÚNICA se puede ver utilizando SQL Server Management Studio, expandiendo el nodo de las Claves debajo de la tabla seleccionada. Usted también puede ver el índice creado automáticamente que se utiliza para garantizar la unicidad de los valores de columna. Tenga en cuenta que no podrá eliminar ese índice sin eliminar primero la restricción ÚNICA:

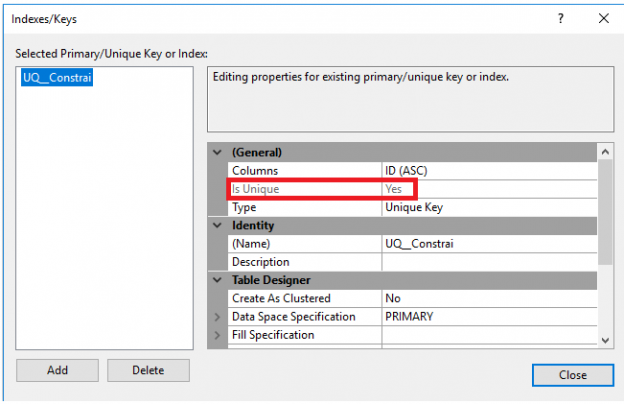
Además de que previamente los comandos T-SQL mostrados anteriormente, la restricción UNIQUE también se puede definir y modificar utilizando SQL Server Management Studio. Haga clic en el botón derecho en la tabla necesaria y elija Diseño. Desde la ventana Diseño, haga clic con el botón derecho en esa ventana y elija Índices/Teclas, desde donde se puede marcar la restricción como ÚNICA, como se muestra a continuación:

Restricción CLAVE PRIMARIA SQL
La restricción PRIMARY KEY consta de una columna o varias columnas con valores que identifican de forma única cada fila de la tabla.
La restricción PRIMARY KEY de SQL se combina entre las restricciones UNIQUE y SQL NOT NULL, donde la columna o el conjunto de columnas que participan en PRIMARY KEY no pueden aceptar el valor NULL. Si la CLAVE PRIMARIA se define en varias columnas, entonces se puede insertar valores duplicados en cada columna individualmente, pero es importante mencionar que los valores de combinación de todas las columnas de CLAVE PRIMARIA deben ser únicos. Tenga en cuenta que solo puede definir una CLAVE PRIMARIA por cada tabla, y se recomienda utilizar columnas pequeñas o INT en la CLAVE PRIMARIA.
Además de proporcionar un acceso rápido a los datos de la tabla, el índice que se crea automáticamente, al definir la CLAVE PRIMARIA de SQL, impondrá cualidad de la unicidad de los datos. La CLAVE PRIMARIA se usa principalmente para imponer la integridad de la entidad de la tabla. La integridad de la entidad garantiza que cada fila de la tabla sea de forma única una entidad identificable.
Se puede advertir que La restricción PRIMARY KEY difiere de la restricción UNIQUE en eso; usted puede crear múltiples restricciones ÚNICAS en una tabla, con la capacidad de definir solo una CLAVE PRIMARIA SQL por cada tabla. Otra diferencia es que la restricción UNIQUE permite un valor NULL, pero la PRIMARY KEY no permite valores NULL.
Supongamos que tenemos la siguiente tabla simple con dos columnas; la identificación y el nombre. La columna de ID se define como una CLAVE PRIMARIA para esa tabla, la que se utiliza para identificar cada fila en esa tabla de tal forma asegurando que no se inserten valores NULL o duplicados en esa columna de ID. La tabla se define usando el script CREATE TABLE T-SQL a continuación:
|
1 2 3 4 5 6 7 8 9 |
USE SQLShackDemo GO CREATE TABLE ConstraintDemo3 ( ID INT PRIMARY KEY, Name VARCHAR(50) NULL ) |
Si intenta ejecutar las tres instrucciones INSERT a continuación:
|
1 2 3 4 5 6 7 8 |
INSERT INTO ConstraintDemo3 ([ID],[NAME]) VALUES (1,'John') GO INSERT INTO ConstraintDemo3 ([NAME]) VALUES ('Fadi') GO INSERT INTO ConstraintDemo3 ([ID],[NAME]) VALUES (1,'Saeed') GO |
Usted Verá que el primer registro se insertará exitosamente y correctamente ya que los valores de ID y Nombre son válidos. La segunda operación de inserción fallará, ya que la columna ID es obligatoria y no puede ser NULL, ya que la columna ID es la CLAVE PRIMARIA SQL. La última instrucción INSERT también fallará ya que el valor de ID proporcionado ya existe y los valores duplicados ya no están permitidos en la CLAVE PRIMARIA, tal como se muestra en el siguiente mensaje de error:

Verificando los valores insertados, usted verá que solo el primer registro se inserta correctamente como se muestra a continuación:

Si usted no proporciona la restricción CLAVE PRIMARIA de SQL con un nombre durante la definición de la tabla, el motor de SQL Server será quien le proporcionará un nombre único como puede ver al consultar el objeto del sistema INFORMATION_SCHEMA.TABLE_CONSTRAINTS a continuación:
|
1 2 3 4 5 6 7 8 |
SELECT CONSTRAINT_NAME, TABLE_SCHEMA , TABLE_NAME, CONSTRAINT_TYPE FROM INFORMATION_SCHEMA.TABLE_CONSTRAINTS WHERE TABLE_NAME='ConstraintDemo3' |
Con el siguiente resultado en nuestro ejemplo:

La instrucción ALTER TABLE… DROP CONSTRAINT T-SQL se puede usar fácilmente para cargar la CLAVE PRIMARIA previamente definida usando el nombre derivado del resultado anterior:
|
1 2 3 4 |
ALTER TABLE ConstraintDemo3 DROP CONSTRAINT PK__Constrai__3214EC27E0BEB1C4; |
Si usted intenta ejecutar las anteriormente fallidas instrucciones INSERT, verá que el primer registro no se insertará ya que la columna ID no permite valores NULL. El segundo registro se insertará con éxito, ya que esto no impide que los valores duplicados se inserten después de cargar la CLAVE PRIMARIA de SQL, como se muestra a continuación:

Intentando nuevamente añadir la restricción CLAVE PRIMARIA SQL usando la consulta ALTER TABLE T-SQL a continuación se tiene que:
|
1 2 3 4 |
ALTER TABLE ConstraintDemo3 ADD PRIMARY KEY (ID); |
La operación fallará, ya que al verificar primero los valores de ID existentes para cualquier valor NULL o duplicado, SQL Server encuentra un valor de ID duplicado de 1 como se muestra en el siguiente mensaje de error:

Al verificar los datos de la tabla, también se mostrará el valor duplicado:

Para agregar la restricción PRIMARY KEY, lo primero que debemos hacer es borrar los datos, eliminando o modificando el registro duplicado. Aquí cambiaremos el segundo valor de ID de registro usando la instrucción siguiente de ACTUALIZAR:
|
1 2 3 |
UPDATE ConstraintDemo3 SET ID =2 WHERE NAME ='Saeed' |
Luego, intente añadir la CLAVE PRIMARIA de SQL, que ahora se creará con éxito:

La restricción CLAVE PRIMARIA de SQL también se puede definir y modificar mediante SQL Server Management Studio. Haga clic en el botón derecho en su tabla y luego elija Diseño. Desde la ventana Diseño, haga clic con el botón derecho en la columna o conjunto de columnas que participarán en la restricción PRIMARY KEY y en la opción Establecer PRIMARY KEY, lo que desmarcará automáticamente la casilla de verificación Permitir NULL, como se muestra a continuación:

Por favor Consulte el siguiente artículo de la serie Restricciones de SQL Server de uso común: FOREIGN KEY, CHECK y DEFAULT el que describe otras tres restricciones de SQL Server.
Enlaces útiles
- Restricciones
- Restricciones ÚNICAS
- Restricciones ÚNICAS
- • Los beneficios, costos y documentación de las restricciones de la base de datos

He is a Microsoft Certified Solution Expert in Data Management and Analytics, Microsoft Certified Solution Associate in SQL Database Administration and Development, Azure Developer Associate and Microsoft Certified Trainer.
Also, he is contributing with his SQL tips in many blogs.
View all posts by Ahmad Yaseen
- Restricciones en SQL Server: SQL NOT NULL, UNIQUE y SQL PRIMARY KEY - December 16, 2019
- Operaciones de copia de seguridad, truncamiento y reducción de registros de transacciones de SQL Server - November 4, 2019
- Qué elegir al asignar valores a las variables de SQL Server: sentencias SET vs SELECT T-SQL - November 4, 2019